.png?width=1000&height=140&name=Bluesight%20%2B%20Protenus%20Logo%20%20(1).png "Bluesight + Protenus Logo (1)")
Share this

by Ellen Ambrose, Protenus on March 23, 2020
Scala for data science. These words may fill many data scientists with fear and uncertainty--others may even react with indignation. After all, doesn’t our Python toolkit give us everything we need for exploring data, training algorithms, visualizing results, and making discoveries? What is the benefit of throwing a new language into the mix, especially one with a decidedly less intuitive feel for many of us coming from academic research backgrounds?
And yet, Scala is an integral part of the data science skill set at Protenus. It’s the language of our production analytics applications as well as many of our internal tools for exploring data, assembling feature sets, and training classifiers. Here’s a look at how the analytics team at Protenus embraced the use of Scala and what we’re getting out of it today.
Alert Generator 2.0
As the analytics component of our privacy product, the Privacy Alert Generator (AG) is the application that sifts through millions of interactions between employees and medical records each day to detect possible breaches. I joined the company in the summer of 2016, just as an effort was beginning to re-write this application into a more mature, stable state. AG 1.0, originally written in Python, was the outgrowth of the original analytics prototype. It produced good results, but it was complicated and volatile, with a constant onslaught of bug tickets frequently caused by unexpected types or missing data coming from our customers’ data feeds. A full redesign was in order and a decision needed to be made.
Scala was already established in Protenus’ tech stack, and bringing the analytics applications in line came with a number of perks. It would allow us better integration, shared tooling, and enhance the ability of our engineering team to contribute across multiple codebases. All of this aligned well with our company values of shared consciousness and fluid team compositions. Additionally, Scala is statically typed with benefits like the elegant handling of missing data using Options to address one of our biggest pain points from AG 1.0. Finally, Scala is the native language of Spark, which features the most advanced API and the best performance. Through this lens, the choice was made to write AG 2.0 in Scala.

Written in Scala, AG 2.0 symbolized the maturation of the product, a strong engineering hand to support a data science innovation, and a chance to create the stability and robustness that we desperately needed to scale.
Machine Learning with Scala and Spark
Spark is an essential component of our analytics. Although our main offering is identifying the proverbial needle in the haystack, we analyze every data point equally. That means that for us, 99% of running a trained classifier in production is feature generation, done with Spark. This is in contrast to another approach to anomaly detection--rule out 90% of behavior as “normal” based on some simple measures and then generate your feature set on the remaining data points. Our approach means generating features on each of the millions of interactions a day, which requires not only parallelization but also some hefty groupBys and joins. Think about answering the question, “How many patients accessed by this health care employee in the past month were treated in the same department?” It seems simple enough, but it requires joining Dataset[PatientsAccessedLastMonth] to Dataset[DepartmentsVisited], grouping by user, aggregating, and joining back into Dataset[PatientsAccessedToday]. This is the kind of computation we’re doing for many of the features in our set. It’s computationally expensive, but it’s worth it to us to be able to give our customers insight into every point in their data, not just those that pass certain criteria.
Once feature generation is complete, calling a trained classifier is simple in Scala. Here’s what it looks like:

That’s it. Training a classifier isn’t much harder thanks to the simple pipeline Scala API offered by Spark MLlib. We maintain a classifier training code base that contains some standard as well as custom transformers which we use to handle missing data.
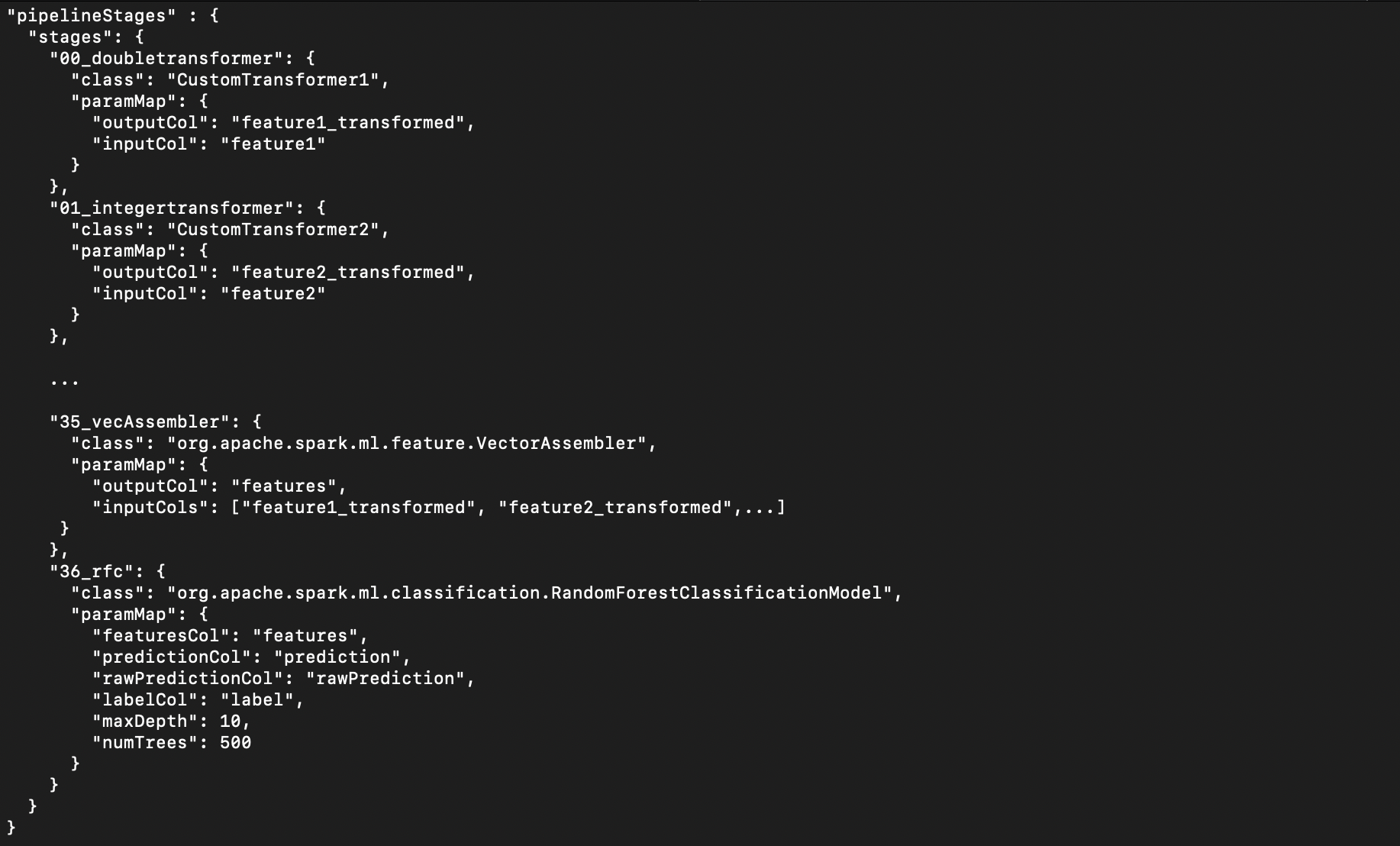
There is an (admittedly limited) number of classifier algorithms available which are easy to interchange within the pipeline and which have been suitable for our needs thus far. This code also produces the output we need for performance evaluation and monitoring.
Data Science at Protenus
I’ve talked a lot about software development and writing production code which may seem at odds with preconceptions about the role of a data science team. In fact, data science is not a distinct entity at Protenus. Our AI teams consist of data scientists and engineers alike, and the boundaries between roles are largely defined by the individuals and their particular interests and strengths. In a team accustomed to wearing many hats, adopting Scala was just another opportunity to explore and grow. Sometimes Python is the best tool for the tasks at hand, and in those cases that is what we turn to, but even in data exploration and feature prototyping we’ve been able to leverage Scala with strong results.
Conclusion

The acceptance of Scala as a language used by our data scientists is a reflection of the Protenus culture and the willingness of the team to grow and adopt the best tools for the job. Scala isn’t our only tool, but it’s one that has brought us the ability to elevate our product to the next level, creating something new, different, and built to last.
Share this
Subscribe by email
You May Also Like

Conserving Resources with Compliance Analytics: A 5-Step Implementation Guide

Enabling Greater Healthcare Efficiency with Protenus AI Technology
